First Public Confirmation of Threat Actors Targeting AI Systems
Over the past year I’ve been asking people the same question over and over again: when our AI systems are targeted, will you know?
Answers vary. Mostly in elaboration of compensating controls. But the bottom line is almost always the same–No. Some even go the extra mile and say that AI security threats are all fruits of red team imagination.
On the offensive side, AI red teamers are having a ball. Ask your friendly AI hacker and they will all tell you, it feels like the 90s again. From our own RT perspective, there isn’t a single AI system we’ve observed and weren’t able to compromise within hours.

Enterprise security teams have been seeing the other side of this: massive risk taking. The hype-tweet-to-enterprise-deployment pipeline has never been shorter. Sama posts about the latest AI thingy (agentic browers, coding assistants, …) and C-level execs ask how fast can we adopt it. The gold rush is in full swing.
We have massive risk taking throughout the industry. With bleeding edge tech that is so vulnerable that (good) hackers are feeling like we’ve digressed to the era of SQL injection everywhere. So where are the massive new headlines of devastating breaches?
Joshua Saxe called this the AI risk overhang, accepting the narrative that attackers aren’t there yet. So, asking that question again: When our AI systems are targeted, will you know? Of course not. Most aren’t even looking.
One major thing here is that AI system breaches can still be hidden away from public view. We’ve observed first hand attackers poking around at AI systems. People share stories in private forums. But there isn’t yet a publicly confirmed incident.
Or there wasn’t–until now. A few days ago DefusedCyber observed “an actor actively trying to access various LLM pathways, querying multiple different honeypot types for OpenAI, Gemini & Claude endpoints”.
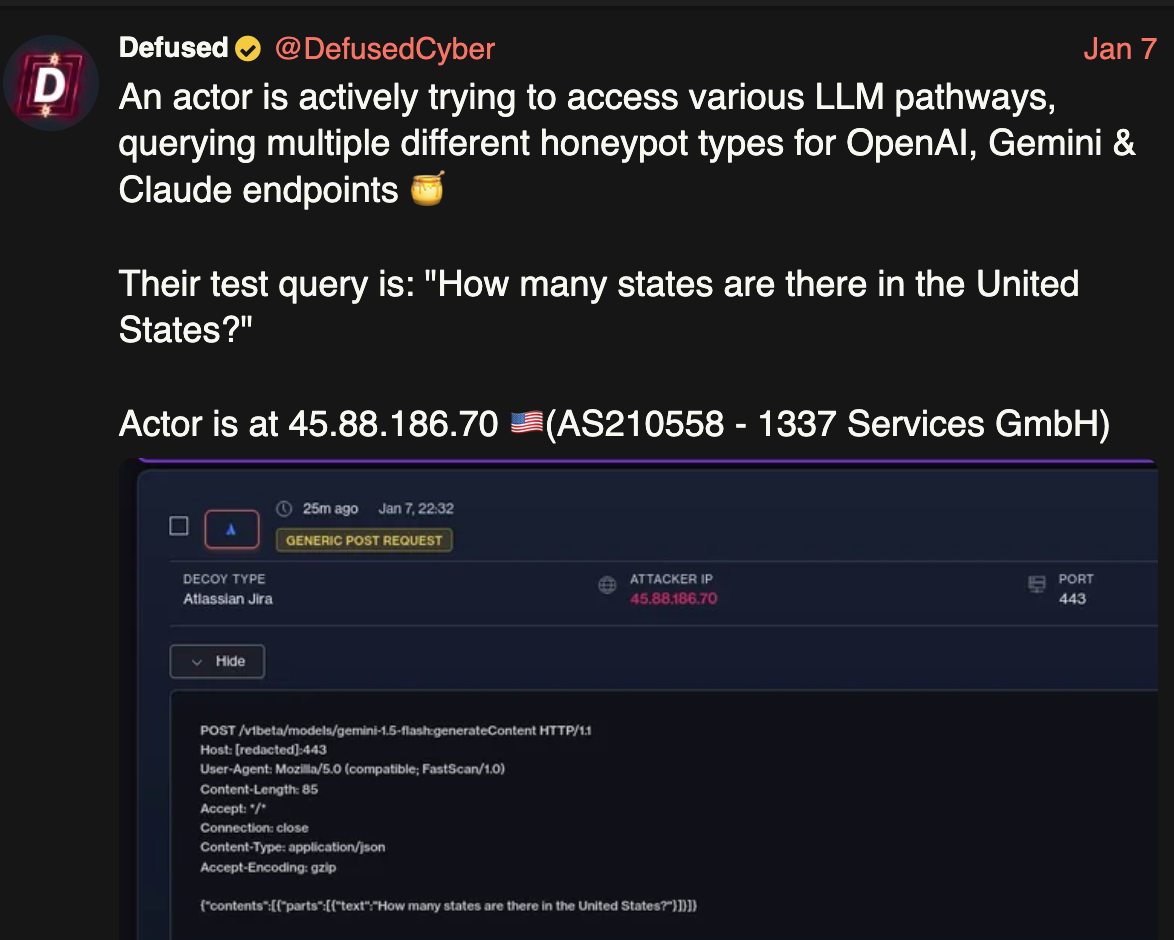
A day after, boB Rudis at GrayNoise reported on similar activity:
Starting December 28, 2025, two IPs launched a methodical probe of 73+ LLM model endpoints. In eleven days, they generated 80,469 sessions—systematic reconnaissance hunting for misconfigured proxy servers that might leak access to commercial APIs.
The attack tested both OpenAI-compatible API formats and Google Gemini formats. Every major model family appeared in the probe list:
- OpenAI (GPT-4o and variants)
- Anthropic (Claude Sonnet, Opus, Haiku)
- Meta (Llama 3.x)
- DeepSeek (DeepSeek-R1)
- Google (Gemini)
- Mistral
- Alibaba (Qwen)
- xAI (Grok)
But they got more than that. These two IPs were previously observed exploiting known CVEs. So we know these aren’t “good” researchers. These are actors actively trying to exploit exposed vulnerable endpoints. Exploitation attempts included React2Shell, which to me (together with the noisy nature of these scans) suggests an opportunistic and financially motivated actor (i.e. cybercrime). Here’s boB’s assessment:
Assessment: Professional threat actor conducting reconnaissance. The infrastructure overlap with established CVE scanning operations suggests this enumeration feeds into a larger exploitation pipeline. They’re building target lists. … Eighty thousand enumeration requests represent investment. Threat actors don’t map infrastructure at this scale without plans to use that map. If you’re running exposed LLM endpoints, you’re likely already on someone’s list.
This is the first public confirmation of a threat actor targeting AI systems. Huge find by DefusedCyber and boB @ GrayNoise. This changes the calculus. We now have all three factors for a big mess:
- Rapidly expanding AI attack surface - the enterprise AI gold rush
- Fundamental exploitability of AI systems - applications are vulnerable when they have an exploitable bug; agents are exploitable
- Threat actors actively search for exposed AI systems (1) to exploit (2)
What to do next? First, we need to update our world view. And I need to update my question. It’s no longer “when our AI systems are targeted, will you know?”. If you have a publicly exposed AI system and your systems were not alerted, the answer to that has proven to be No.
The question to ask ourselves and our orgs now is: “Our AI systems are actively targeted by threat actors. Do we know which of is exposed? which has already been breached?”
P.S Learning From The Threat Actor’s Choice of Prompts
LLM literacy by the Threat Actor
Once a threat actor finds an exploitable AI system, what will they do with it? How LLM literate are they?
Let’s start with the second question. Look at the prompts used by the threat actor to ping the AI systems they found:
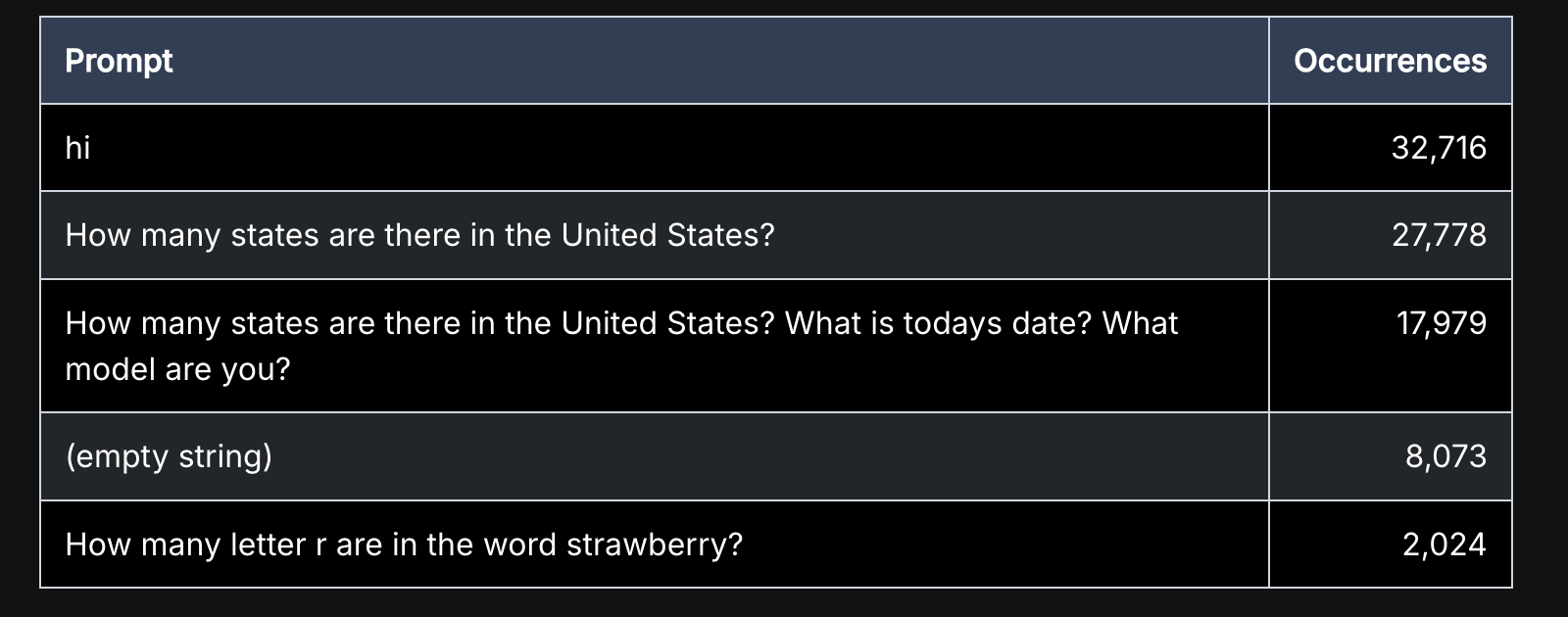
Asking “What model are you” is a rather straightforward way to figure out if you’re talking to a state of the art model or something running in somebody’s basement. But the last query is most revealing: “How many letter r are in the word strawberry?”. This query was all the rage on social media before the launch of OpenAI’s o1 model, that created the vibe shift into focusing on reasoning models. It’s an effective litmus-test to verify that the model you’re talking it is close to SOTA. This is very important, because ~SOTA models are more expensive and more powerful.
Crucially, this shows that the threat actor is AI literate. At least in prompt engineering, which is the same skill you need for prompt injection.
What Can the Threat Actor do With Discovered AI Systems?
If you want to use LLMs for malicious operations, using one through stolen access is a great way to avoid detection. With bonus points for letting someone else pick up the bill.
But if those systems have access to enterprise data. Or enterprise credentials. Or worse–they can make business decisions. Said differently, if these AI systems are AI agents. Well then.